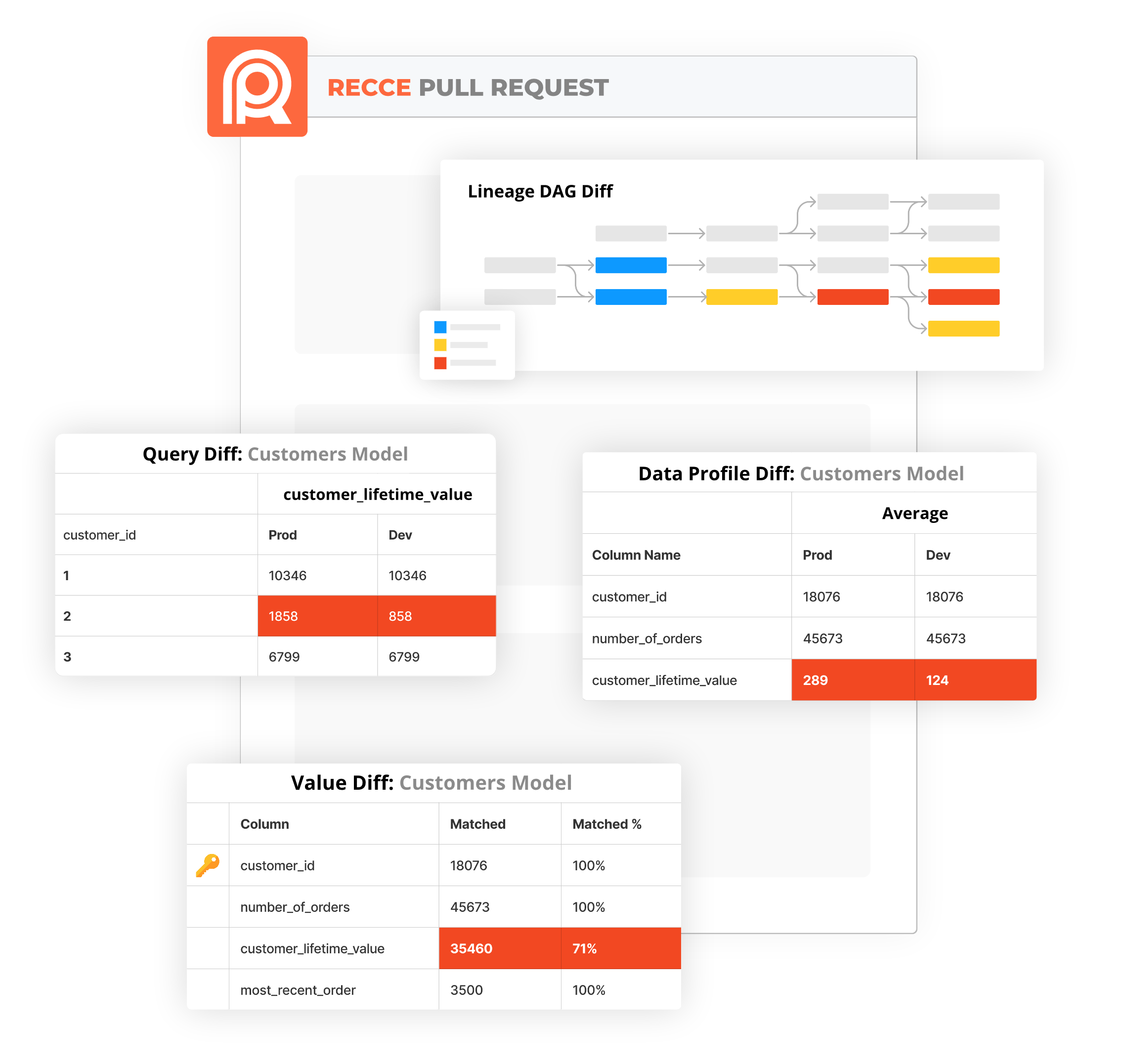
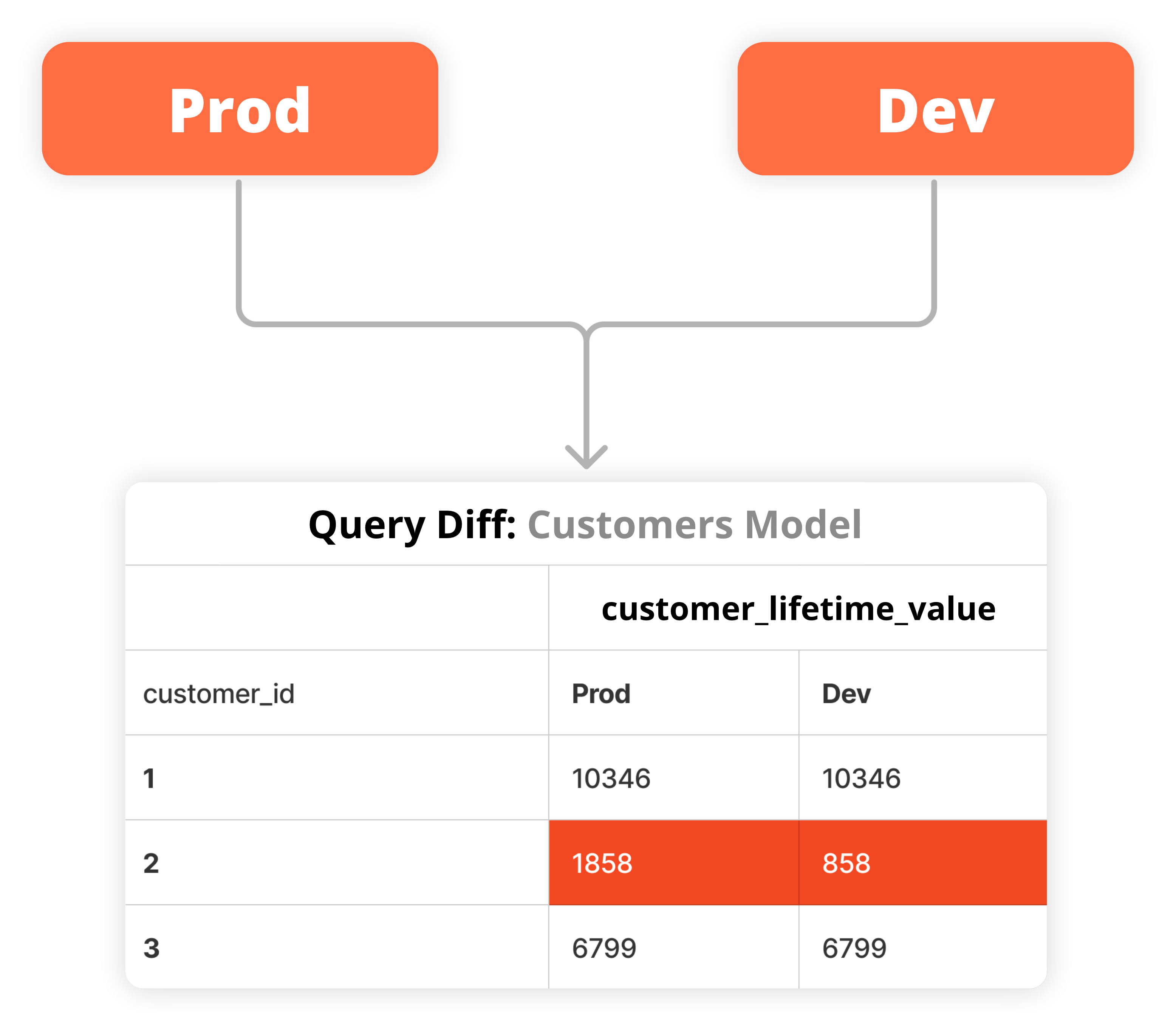
Cross-environment diffs with Recce help speed up the QA process for pull request review. Quickly check data impact by comparing modeling changes with production data - No need to craft complex queries yourself, or deal with configurations for multiple tools.
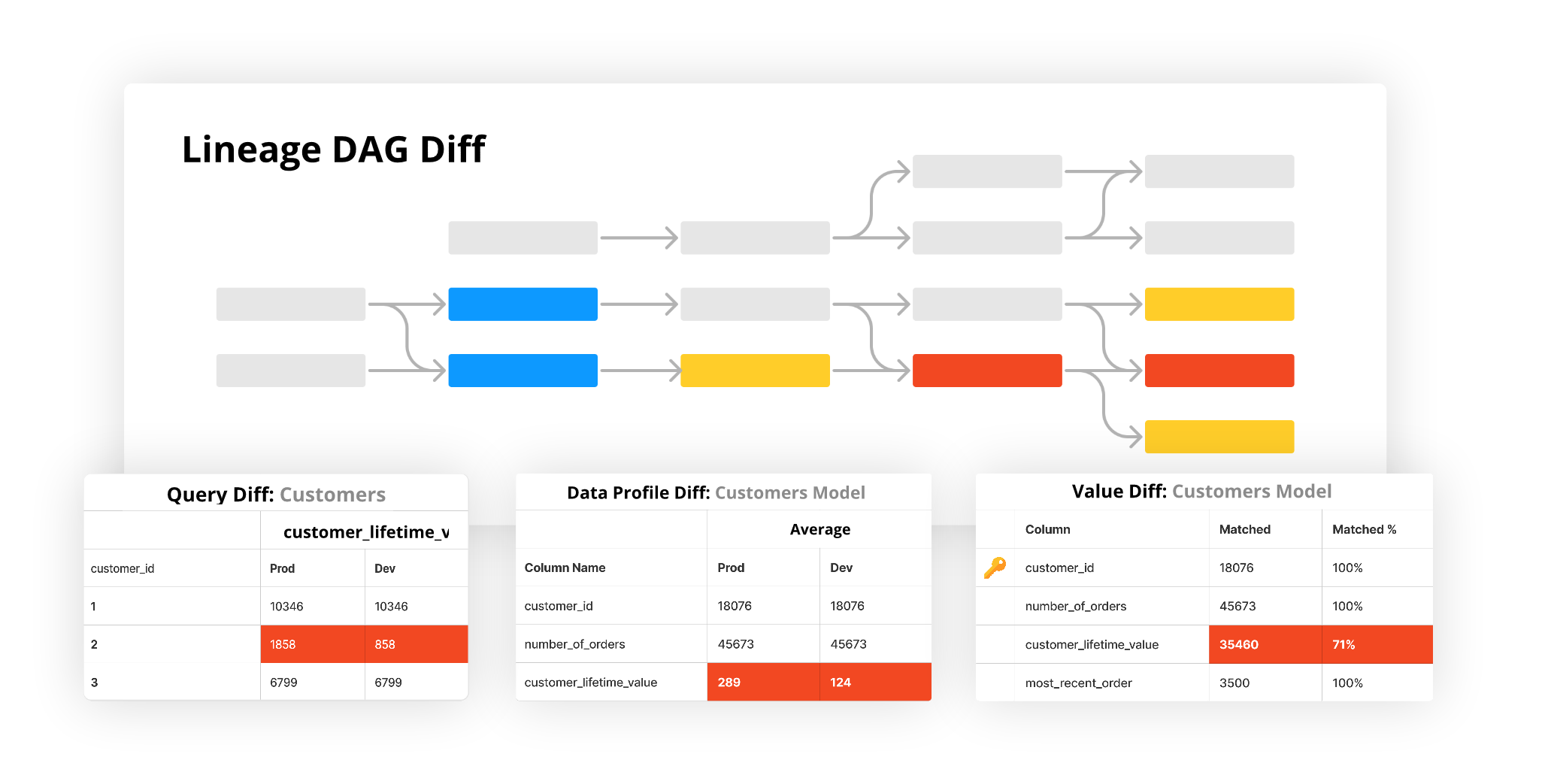
Recce is feature-packed with a diff for every type of validation you'll need to ensure proof-of-correctness of your modeling changes. Starting from the Lineage DAG-Diff interface, Recce shows you the part of your DAG that has been impacted by your changes. It's the interface for your data-change reconnaissance mission.
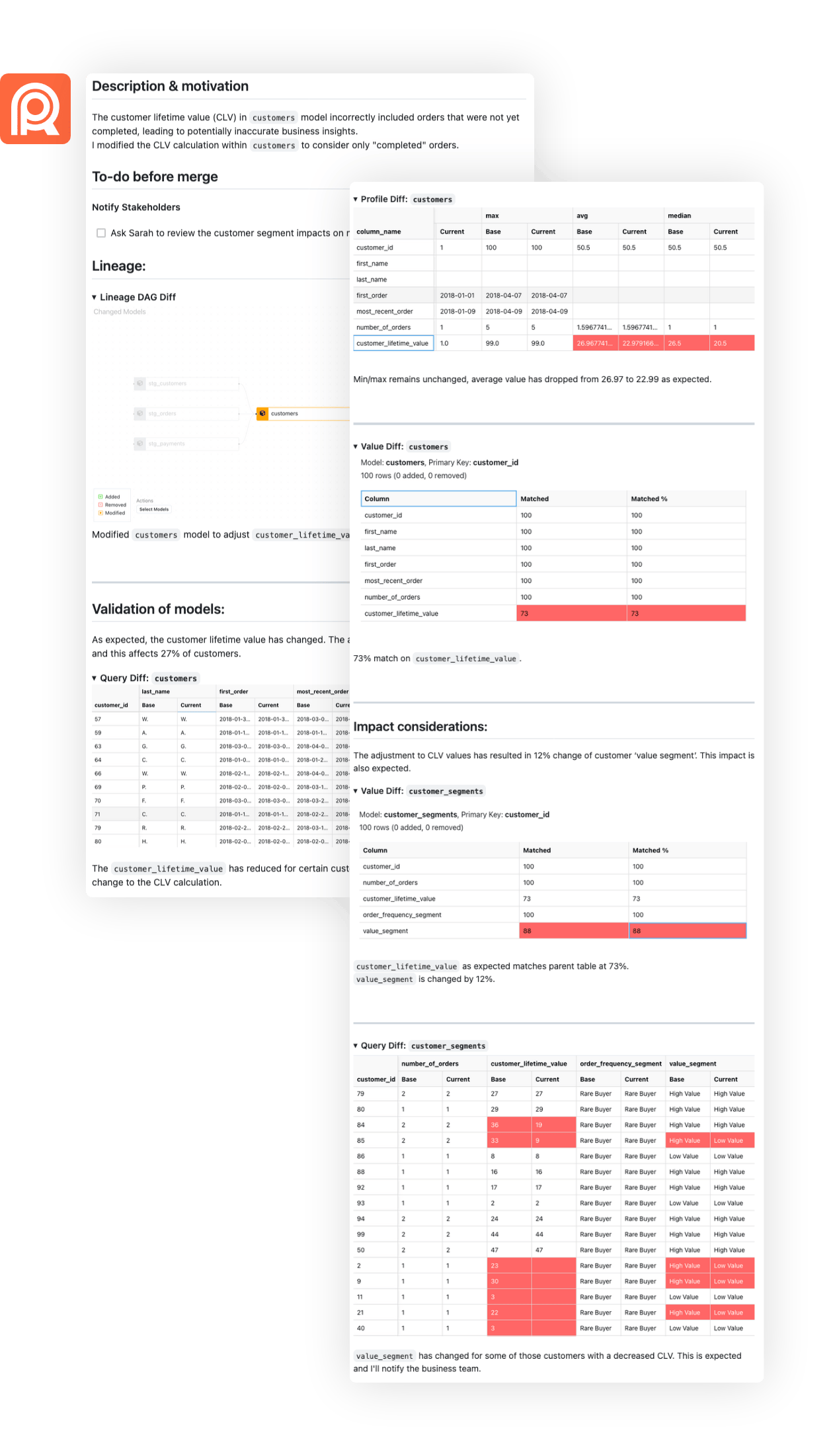
Curate the checks you need into a list of reproducible validations for use in your pull request comment.
© 2024 InfuseAI